


Introduction
Hello, devs I know most of us are always excited about building applications that are scalable and following standard coding principles. Setting up some tools to help us build and scale applications fast has been my target anytime I build a project.
Therefore, this article will put us through the steps of setting up CI/CD with GitHub action in a nextjs project. For most of us, who are not aware of what CI/ CD means, it means Continous Integration and Continous Delivery. Continuous integration (CI) automatically builds, tests, and integrates code changes within a shared repository while Continuous delivery (CD) automatically delivers code changes to production-ready environments for approval. At times we mix up Continous Delivery with Continous Deployment, Continous Deployment actually means automatic deployment of code changes to customers directly. There are several means of setting up CI/CD, but in this article, we will only be discussing the GitHub action workflow.
Project setup
To proceed with the setup, we must have a nextjs project setup first, below is the cli to setup a nextjs with typescript boilerplate:
npx create-next-app@latest --typescript
# or
yarn create next-app --typescript
# or
pnpm create next-app --typescript
The command will setup a nextjs project in typescript, I already have my own setup with nextjs and typescript which looks like this below
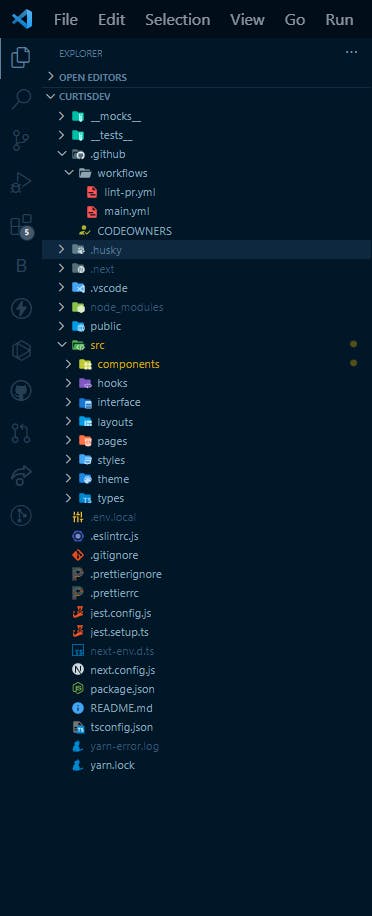
The current structure I have is set up with eslint, prettier and husky, the most essential part I want you to pay attention to is the folder name with .github which contains the setup for the CI/CD.
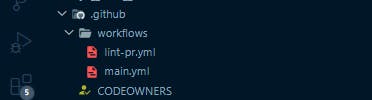
For GitHub to identify the setup, the folder name must be written as workflows, if not, the GitHub action will not run a pipeline for the setup. Here comes the crucial part, DevOps always have files with .yml as their file extension, these files are responsible for running a job on the pipelines and they are all written to handle different actions. Before we proceed let's briefly talk about YAML files or .yml as a file extension.
YAML or .yml files
YAML stands for YAML Ain't Markup Language, but it originally stood for Yet Another Markup Language. YAML is a human-readable data serialization language, just like XML and JSON.
Serialization is a process where one application or service that has different data structures and is written in a different set of technologies can transfer data to another application using a standard format.
In other words, serialization is about translating, converting, and wrapping up a data structure in another format.
The data in the new format can be stored in a file or transmitted to another application or service over a network. YAML is a widely used format for writing configuration files for different DevOps tools, programs, and applications because of its human-readable and intuitive syntax.
Code content
Now we can see, why we use a .yml file as the file extension for setting up our GitHub workflow actions. In my own setup, I have two files one is called the main.yml while the other one is called lint-pr.yml.
main.yml
name: Build
on:
push:
branches:
- "**"
workflow_dispatch:
jobs:
build:
runs-on: ubuntu-latest
steps:
# Checks-out your repository under $GITHUB_WORKSPACE, so your job can access it
- uses: actions/checkout@v3
- name: Setup Node
uses: actions/setup-node@v2
with:
node-version: 16.x
- name: Install dependencies
run: yarn install
- name: Lint
run: yarn run lint
The above code shows the content structure of how the main file runs. You will have to give it a name, In my own case, it is Build-you can call yours anything that suits you, and you will have the on, this act on the branch stated in the code and then we have the job, you also state the build and what tools it should run on. Under the build, we will also have steps that contain all the actions to be performed for the pipeline as you can see in the code above you will have to give the name and the run for each of the steps. In my own, case I am using yarn to run the dependencies and linting the code to check for any errors before the code passes the builds.
lint-pr.yml
name: lint-pr
on:
pull_request_target:
types:
- opened
- edited
- synchronize
branches:
- main
jobs:
main:
runs-on: ubuntu-latest
steps:
- name: Setup Node
uses: actions/setup-node@v2
with:
node-version: 16.x
- name: Install commitlint
run: yarn add global @commitlint/cli @commitlint/config-conventional
- name: Configure commitlint
run: echo "module.exports = {extends${{':'}} ['@commitlint/config-conventional']}" > commitlint.config.js
- name: Lint PR
run: echo ${{ github.event.pull_request.title }}
This code is also something similar to the one in the main.yml code. But as we have it here, we specify this build only for a pull request, which tells us that the on has the function to act on any branch on request on the codebase. Inside our steps, we have different run name these are for checking conventional commit and pull request titles if they meet the standard set for it. Now anytime a pull request is made to the main branch this build runs, and if it is not satisfied it will fail and prevent the application from deploying to live.
Builds on Github
Now, that we have seen how the setup is done. Let's take a look at how they run on GitHub. The moment you push your code to GitHub the Action tabs will be set up for each build depending on the branch it acts on. Below is the build I have run on my codebase.
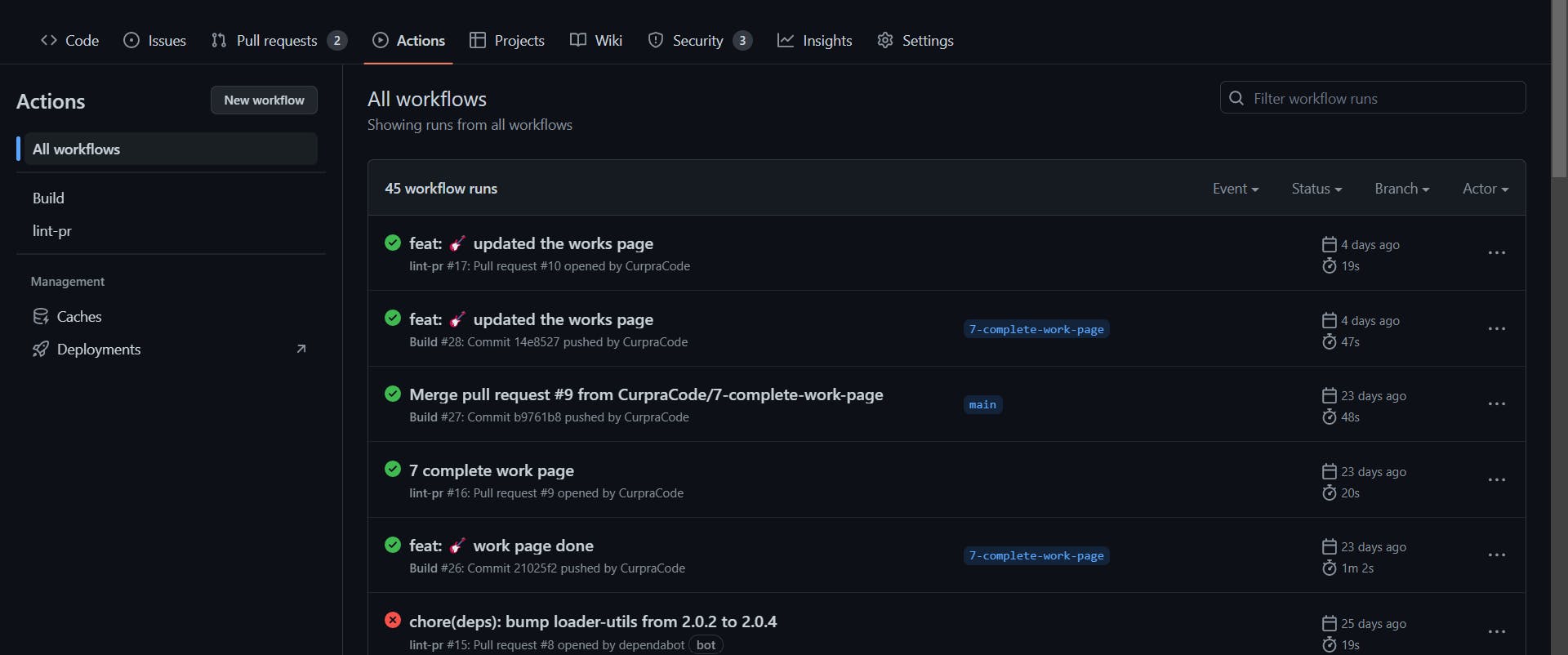
As you can see, we already have several workflows running on the action tab. If you have this after the setup, Congrat, you have just successfully set up CI/CD for your project. This also shows how some are marked as successful and some are marked as cancelled which means failed. To check for what went wrong you can click the name of the pr or commit to see what caused the build from failing. the images below show the one successful and the one that failed.
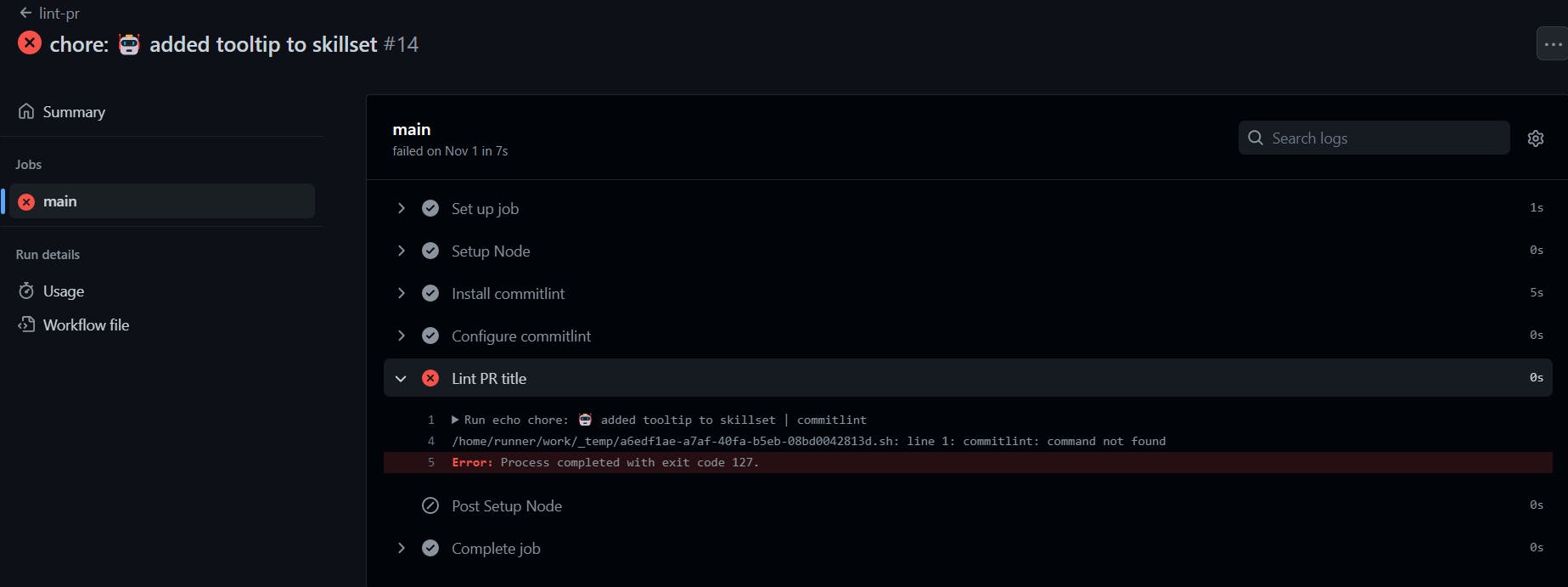
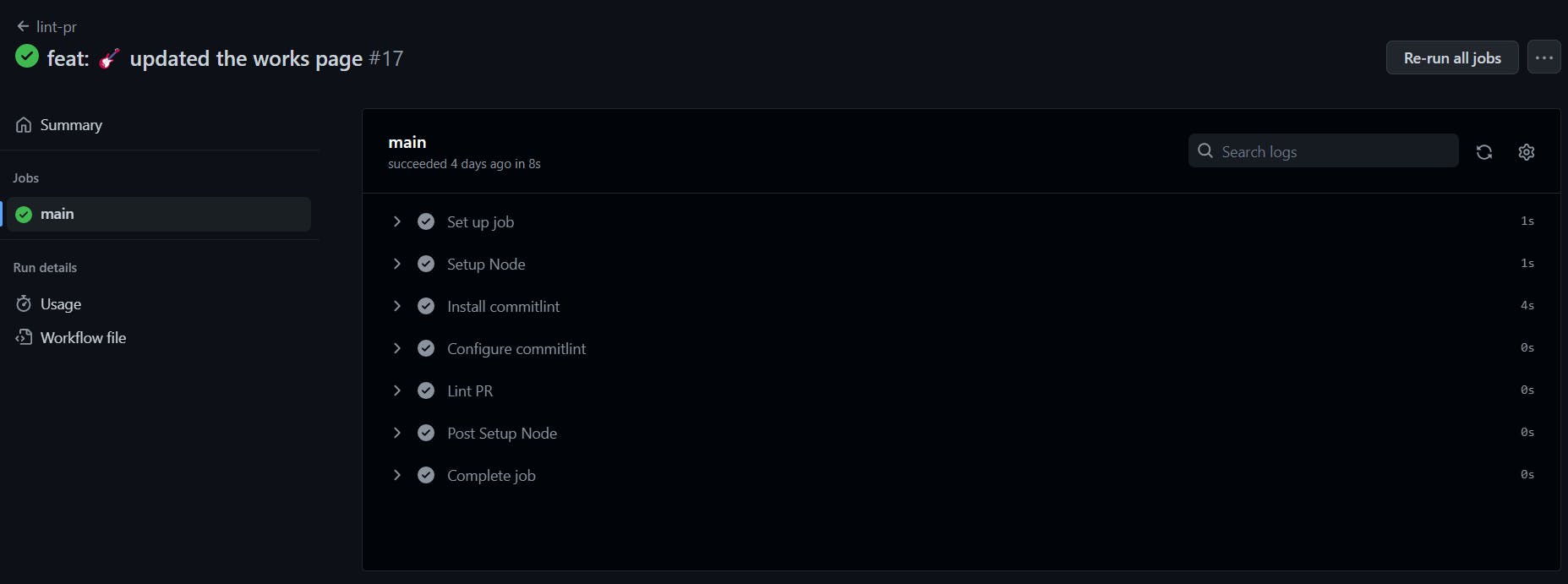
You also have the option to re-run the job to be fully sure of what went wrong. And likewise, this helps you to fix the issue anytime a build fails.
The benefit of CI/CD
Now we can see how the setup flow is done and runs. One might be asking, this can lead to lots of stress and delay in development due to the setup and all the builds that run every time you push your code or make a pull request. Well, I say to you, doing this makes you a better developer and it improves your level of writing code. Below are the advantages or benefits of having a CI/CD setup in your project.
With a CI/CD pipeline, you can test and deploy code more frequently, giving testers the ability to detect issues as soon as they occur and to fix them immediately. You are essentially mitigating risks in real-time.
With a CI/CD pipeline, extensive logging information is generated at each stage of the development process. There are various tools available to analyse these logs effectively and get immediate feedback about the system.
If any new code changes break the production application, you can immediately return the application to its previous state. Usually, the last successful build gets immediately deployed to prevent production outages.
It provides extensive logs for every build as a report.
Conclusion
Yes, a lot of us meant to say, this is essentially the work of a DevOps engineer, but at the same time, it is relevant for us to know this as it will help us to improve our way of coding and develop the habit of improving our skill set.
Finally, this is my first article on technical writing, and I also wish to get feedback from everyone reading this, as I always want to improve my skills the same way I want you to improve your skills.
Cheers, enjoy your holidays in advance.